
Hugging Faceのモデル学習で、モデルをカスタマイズする方法
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データアナリティクス事業本部 機械学習チームの中村です。
Hugging Faceのライブラリの使い方紹介記事第6弾です。
前回はロス関数のカスタマイズでしたが、今回は、モデルをカスタマイズする方法をご紹介します。
モデルの入力をカスタマイズする目的
モデルをカスタマイズしたいと思うケースには、例えば以下のようなものが挙げられます。
- 入力にテキスト以外のデータも含まれる
- 基本的に事前学習モデルが処理対象とするのはテキストのみです。
- そのため、別のデータを入力するにはモデルのカスタマイズが必要になります。
- 分類ヘッドを自分なりにカスタマイズしたい
- テキストのみのデータであっても分類に複雑なヘッドを使いたい。
- デフォルトでは線形層が1つのみとなるため、工夫を凝らしたい
今回はこのような場合に必要となるモデルのカスタマイズについて説明します。
例としては、「入力にテキスト以外のデータも含まれる」ケースを考えてみましょう。
このケースでは、分類ヘッドも併せて変更する必要がありますので、良い例だと考えられます。
実行環境
今回はGoogle Colaboratory環境で実行しました。
ハードウェアなどの情報は以下の通りです。
- GPU: Tesla T4 (GPUメモリ16GB搭載)
- CUDA: 11.2
- メモリ: 13GB
主なライブラリのバージョンは以下となります。
- transformers: 4.24.0
- datasets: 2.6.1
インストール
transformersとdatasetsをインストールします。
!pip install transformers datasets
また事前学習モデルの依存モジュールをインストールします。
!pip install fugashi !pip install ipadic !pip install sentencepiece
ベースとするコード
今回のベースとするコードは以下のとおりです。
import random
from datasets import load_dataset, DatasetDict
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from transformers import TrainingArguments
from transformers import Trainer
from sklearn.metrics import accuracy_score, f1_score
import torch
# データセットのロード
dataset = load_dataset("tyqiangz/multilingual-sentiments", "japanese")
# 実験のためデータセットを縮小したい場合はコチラを有効化
random.seed(42)
dataset = DatasetDict({
"train" : dataset['train']\
.select(random.sample(range(dataset['train'] .num_rows), k=1000)),
"validation": dataset['validation']\
.select(random.sample(range(dataset['validation'].num_rows), k=1000)),
"test" : dataset['test']\
.select(random.sample(range(dataset['test'] .num_rows), k=1000)),
})
# トークナイザのロード
model_ckpt = "cl-tohoku/bert-base-japanese-whole-word-masking"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
# トークナイズ処理
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)
dataset_encoded = dataset.map(tokenize, batched=True, batch_size=None)
# 事前学習モデルのロード
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_labels = 3
model = (AutoModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels)
.to(device))
# メトリクスの定義
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
f1 = f1_score(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1}
# 学習パラメータの設定
batch_size = 16
logging_steps = len(dataset_encoded["train"]) // batch_size
model_name = "sample-text-classification-bert"
training_args = TrainingArguments(
output_dir=model_name,
num_train_epochs=2,
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
evaluation_strategy="epoch",
disable_tqdm=False,
logging_steps=logging_steps,
push_to_hub=False,
log_level="error",
)
# Trainerの定義
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=dataset_encoded["train"],
eval_dataset=dataset_encoded["validation"],
tokenizer=tokenizer
)
# トレーニング実行
trainer.train()
この内容についての解説は以下の記事を参照ください。
またコード中に記載の通り、実験のみを簡易に試されたい方は以下を有効にして試されてください。
逆にフルサイズのデータで試したい方は以下をコメントアウトして使用ください。
# 実験のためデータセットを縮小したい場合はコチラを有効化
random.seed(42)
dataset = DatasetDict({
"train" : dataset['train']\
.select(random.sample(range(dataset['train'] .num_rows), k=1000)),
"validation": dataset['validation']\
.select(random.sample(range(dataset['validation'].num_rows), k=1000)),
"test" : dataset['test']\
.select(random.sample(range(dataset['test'] .num_rows), k=1000)),
})
今回は有効化した前提で記事を書きます。
カスタマイズの準備
データセットの修正
データセットを修正するために可視化してみます。エンコード済みの方を見てみましょう。
dataset_encoded.set_format(type="pandas") dataset_encoded["train"][:10]
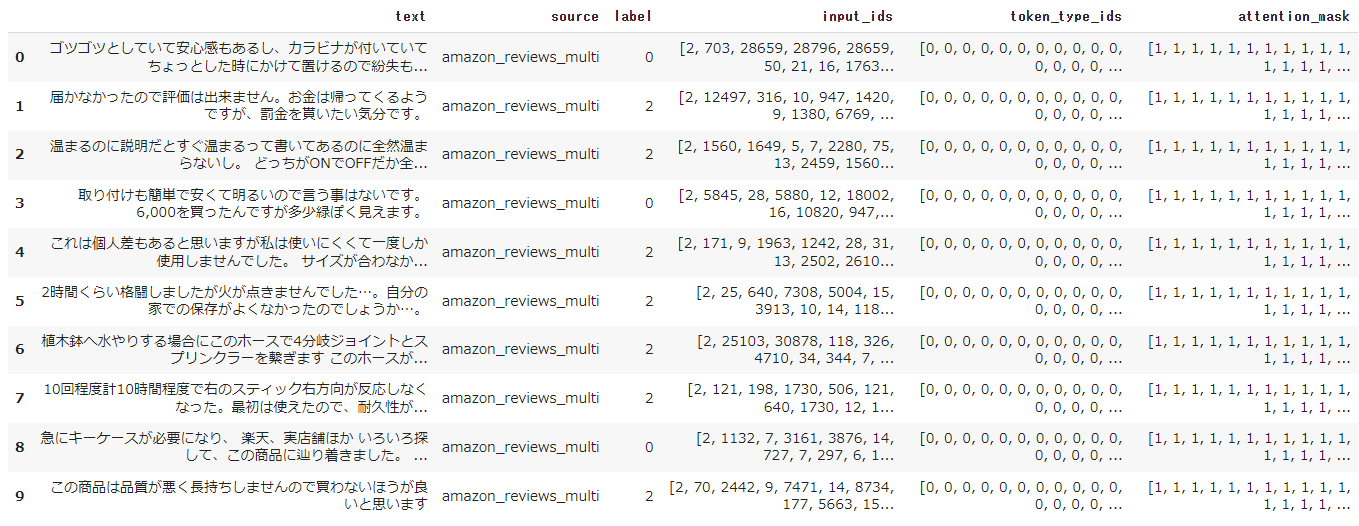
ここのsourceをカテゴリ変数として、入力の一部として扱えるように改変してみます。
dataset_encoded.reset_format() # フォーマットをpandasからリセット
def add_dummy_categorical(batch):
return {"source": random.choice([0,1,2])}
dataset_encoded = dataset_encoded.map(add_dummy_categorical)
再度中身を確認してみます。
dataset_encoded.set_format(type="pandas") dataset_encoded["train"][:10]
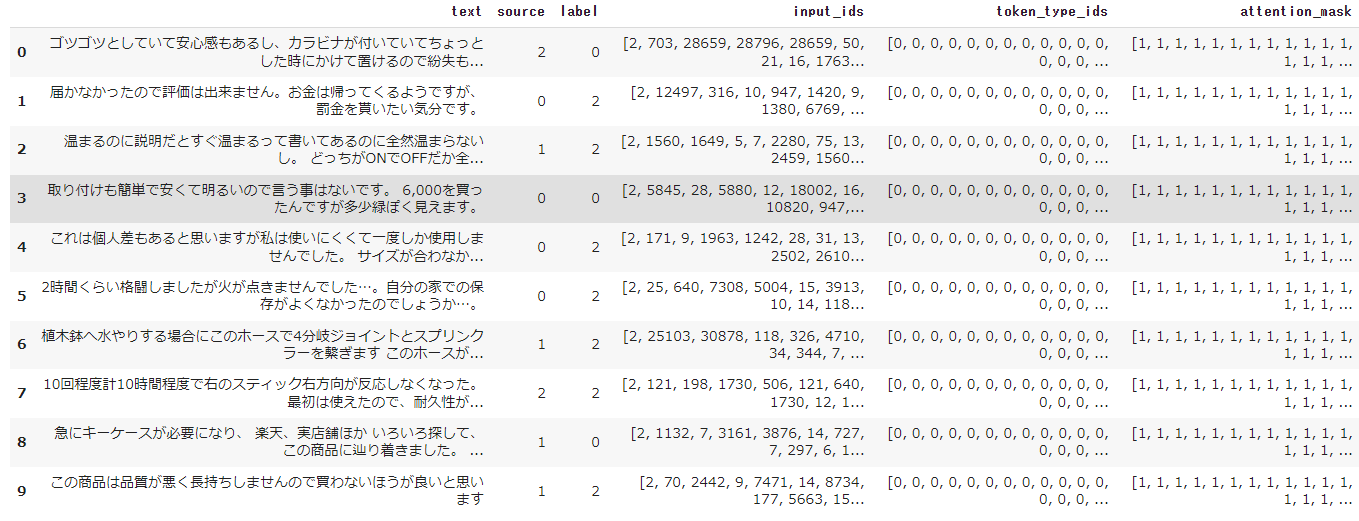
sourceの数値にランダムに0,1,2が入っていることが分かります。これを入力として使用する方法を考えます。
なお、再度フォーマットは戻しておきましょう
dataset_encoded.reset_format() # フォーマットをpandasからリセット
モデルクラスの定義
モデルの入力データをカスタマイズするには、モデルクラスを自身で定義する必要があります。
モデルクラスは、BertPreTrainerdModelのサブクラスとして定義することで、from_pretrainedなどのメソッドがそのまま使用できます。
まずはカスタマイズのことは一旦置いておき、ベースと同じような動作をするモデルクラスを作ってみます。
from torch import nn
from transformers import BertPreTrainedModel, BertModel
from transformers.modeling_outputs import SequenceClassifierOutput
class CustomModelForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
# 系列分類の場合、[CLS]トークンのみの隠れ状態で十分なのでadd_pooling_layer=TrueでOK
self.bert = BertModel(config)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None \
else config.hidden_dropout_prob
)
# 分類ヘッドの用意
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
# 初期化(Body部は事前学習済みの重みをロード、ヘッドはランダム初期化される)
self.post_init()
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None\
, labels=None, **kwargs):
# 隠れ状態を取得
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids, **kwargs
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
少し長いですが、TransformersのBertForSequenceClassificationのソースコードを参考にしています。
詳細は以下をご参照ください。
モデルクラスの定義すれば、以下のようにベースコード同様に学習することが可能です。
model = (CustomModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels)
.to(device))
# Trainerの定義
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=dataset_encoded["train"],
eval_dataset=dataset_encoded["validation"],
tokenizer=tokenizer
)
# トレーニング実行
trainer.train()
モデルクラスのカスタマイズ実施
これでカスタマイズするための準備が整いました。
カスタマイズ自体は簡単に実施できます。基本的にはforwardメソッドの引数にsourceを追加すればOKです。
あとは追加したsourceに関する処理のもろもろを記述します。
from torch import nn
from transformers import BertPreTrainedModel, BertModel
from transformers.modeling_outputs import SequenceClassifierOutput
class CustomModelForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
# 系列分類の場合、[CLS]トークンのみの隠れ状態で十分なのでadd_pooling_layer=TrueでOK
self.bert = BertModel(config)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None \
else config.hidden_dropout_prob
)
# 分類ヘッドの用意
self.dropout = nn.Dropout(classifier_dropout)
# ヘッドのlinear層について、入力の隠れ状態数にsource分の1を加算
# self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.classifier = nn.Linear(config.hidden_size + 1, config.num_labels)
# Initialize weights and apply final processing
# 初期化(Body部は事前学習済みの重みをロード、ヘッドはランダム初期化される)
self.post_init()
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None\
, labels=None, source=None, **kwargs):
# 隠れ状態を取得
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids, **kwargs
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
# bertの出力とconcatする
source = torch.unsqueeze(source, 1)
merge_output = torch.concat([pooled_output, source], 1)
# concatしたものをヘッドに入力する
logits = self.classifier(merge_output)
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
これで、同様に以下のコードで学習することが可能です。
model = (CustomModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels)
.to(device))
# Trainerの定義
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=dataset_encoded["train"],
eval_dataset=dataset_encoded["validation"],
tokenizer=tokenizer
)
# トレーニング実行
trainer.train()
これで、入力をカスタマイズしたモデルをトレーニングすることができました。
発展:configでsourceの使用を制御する
入力にsourceを追加するカスタマイズを実施しましたが、後からオンオフしたいこともあるかと思います。
そのためには、まずconfigをカスタマイズする必要があります。
それには、以下のようなBertConfigのサブクラスを作成することで実現できます。
from transformers BertConfig
class CustomBertConfig(BertConfig):
def __init__(self, use_source_column=False, **kwargs):
super().__init__(**kwargs)
self.use_source_column = use_source_column
そして、モデルクラス側にも対応する修正を入れます。
ポイントとしては、config_classというクラス変数に、カスタマイズしたconfigであるCustomBertConfigを与えることです。
これにより、クラス内部でカスタマイズしたconfigを扱うことが可能になります。
class CustomModelForSequenceClassification(BertPreTrainedModel):
config_class = CustomBertConfig
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.use_source_column = config.use_source_column
# 系列分類の場合、[CLS]トークンのみの隠れ状態で十分なのでadd_pooling_layer=TrueでOK
self.bert = BertModel(config)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None \
else config.hidden_dropout_prob
)
# 分類ヘッドの用意
self.dropout = nn.Dropout(classifier_dropout)
if self.use_source_column:
# ヘッドのlinear層について、入力の隠れ状態数にsource分の1を加算
self.classifier = nn.Linear(config.hidden_size + 1, config.num_labels)
print(f"use_source_column: {self.use_source_column}")
else:
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
# 初期化(Body部は事前学習済みの重みをロード、ヘッドはランダム初期化される)
self.post_init()
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None\
, labels=None, source=None, **kwargs):
# 隠れ状態を取得
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids, **kwargs
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
if self.use_source_column:
# bertの出力とconcatする
source = torch.unsqueeze(source, 1)
merge_output = torch.concat([pooled_output, source], 1)
# concatしたものをヘッドに入力する
logits = self.classifier(merge_output)
else:
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
確認のために、print文も入れておきました。これで、以下を実行すると有効に働いていることが検証できます。
model = (CustomModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels)
.to(device))
# Trainerの定義
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=dataset_encoded["train"],
eval_dataset=dataset_encoded["validation"],
tokenizer=tokenizer
)
# トレーニング実行
trainer.train()
まとめ
いかがでしたでしょうか?
今回は自分なりの工夫をこらしたモデルを使いたくなった場合に必要となる、モデルのカスタマイズについて記事にさせていただきました。 ドキュメント上もあまり例示されて、使い方が示されていないため少し実装に苦労しました。
本記事がHugging Faceを使われる方の参考になれば幸いです。







